Dbs101_flippedclass11
Unit 11: Concurrency Control
Locks
A lock is a mechanism that allows transactions to gain either read or write access to data, ensuring that conflicts are prevented and data isolation is maintained. Its purpose is to coordinate access to shared resources, preventing multiple transactions from modifying the same data simultaneously, which could lead to data inconsistencies or corruption. By acquiring a lock, a transaction can safely read or modify data without interference from other concurrent transactions, thereby preserving data integrity and ensuring that each transaction operates on a consistent view of the data.
Why lock resources?
- Preventing Conflicts: Locks ensure multiple transactions don’t modify the same data item simultaneously, avoiding inconsistencies.
- Mutual Exclusion: Only one transaction holds a lock for modification at a time, serializing access and preventing data corruption.
- Data Integrity: By controlling access, locks safeguard data from being left in an unexpected state due to conflicting modifications.
- Isolation Levels: Locks help enforce the desired level of isolation between concurrent transactions.
Difference Between Lock and Latch in Database
Locks:
- Focus: Logical data access control.
- Scope: Granularity can vary - tables, rows, or even indexes.
- Duration: Held for the entire transaction duration.
- Types: Different modes like shared (read) or exclusive (write) for controlling access based on isolation level.
- Control: Developers and applications can manage locks through transactions.
- Purpose: Ensure data consistency across concurrent transactions by preventing conflicting modifications.
Latches:
- Focus: Memory management and internal synchronization.
- Scope: Protect specific memory structures like data pages in the buffer pool.
- Duration: Short-lived, acquired only for the specific operation on the memory structure.
- Type: Typically offer exclusive access, ensuring data consistency within the memory area.
- Control: Internal to the database engine, not directly controllable by developers.
- Purpose: Maintain internal consistency of data in memory during operations like reading, writing, or flushing to disk.
Two main modes of Locks
Shared (S) Lock:
- When a transaction Ti acquires a shared lock on a data item Q, it is allowed to read Q, but not modify or write to it.
- Multiple transactions can hold shared locks on the same data item simultaneously, allowing concurrent read access.
- A shared lock prevents any other transaction from acquiring an exclusive lock on the same data item, ensuring read consistency.
Exclusive (X) Lock:
- When a transaction Ti acquires an exclusive lock on a data item Q, it is allowed to both read and write to Q.
- Only one transaction can hold an exclusive lock on a data item at any given time, ensuring exclusive access.
- An exclusive lock prevents any other transaction from acquiring a shared or exclusive lock on the same data item, effectively blocking all other access.
The rules governing the compatibility of lock modes are:
- Multiple shared locks are compatible with each other, allowing concurrent read access.
- An exclusive lock is incompatible with any other lock (shared or exclusive) on the same data item.
- A shared lock is compatible with other shared locks but incompatible with an exclusive lock on the same data item.
Locks are granted in databases when no other transaction holds a conflicting lock on the same data item, and there are no earlier pending lock requests for that item. This prevents starvation by considering the pending lock request queue in a fair order, such as arrival time, rather than continuously granting new compatible requests ahead of older ones. Granting locks this way ensures data integrity, prevents conflicts, and avoids indefinitely blocking transactions from acquiring necessary locks.
The two-phase locking protocol is a concurrency control method used in database systems to ensure serializability of transactions. It consists of the following two phases:
Growing Phase:
1
- During this phase, a transaction can acquire (lock) the data items it needs to access.
It is not allowed to release (unlock) any data item during this phase.
Shrinking Phase:
- In this phase, the transaction can only release (unlock) the data items it has locked. It is not permitted to acquire any new locks on additional data items.
The key rules of the two-phase locking protocol are:
- After a transaction releases (unlocks) a data item, it can no longer acquire any new locks.
- A transaction cannot acquire a lock after it has released any lock.
Implementation of locking
Lock Manager Process:
- There is a dedicated lock manager process (or component) responsible for handling lock requests, grants, and unlocks from transactions.
Lock Table:
- The lock manager maintains a lock table, which is a data structure that tracks the locks held on various data items.
- For each data item, there is a linked list of lock records, ordered by the arrival time of the lock requests.
Lock Request Handling:
- When a transaction requests a lock on a data item, the lock manager adds a new lock record to the end of the linked list for that data item.
- Lock requests are granted if they are compatible with the existing locks held on the data item and if there are no earlier pending lock requests.
- The order of lock requests in the linked list ensures fairness and prevents starvation.
Unlock Handling:
- When a transaction unlocks (releases) a data item, the lock manager removes the corresponding lock record from the linked list for that data item.
- Removing a lock record may allow later pending lock requests in the linked list to be granted, as they may now be compatible with the remaining locks.
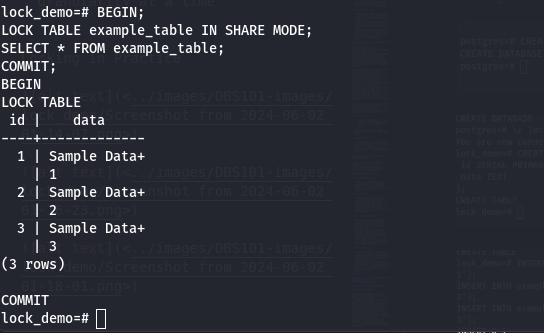
Locking in Practice
SHARE Mode : Allows read and schema modification operations but not data modification operations within the same transaction.
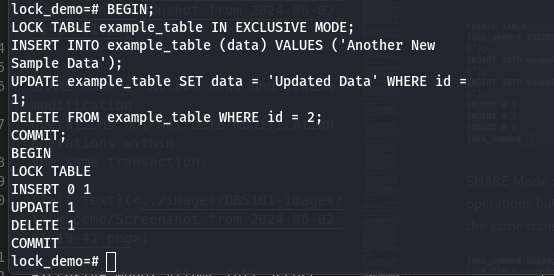
EXCLUSIVE Mode: Allows full access (read, write, delete) to the table, blocking all other transactions.
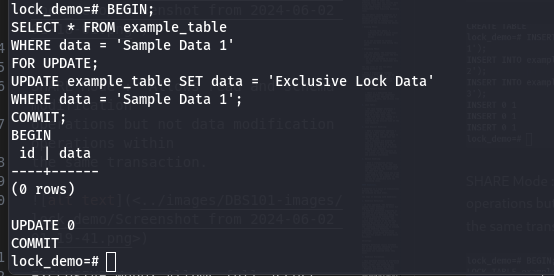
FOR UPDATE: Acquires an exclusive lock on the selected rows, allowing modifications on those rows.
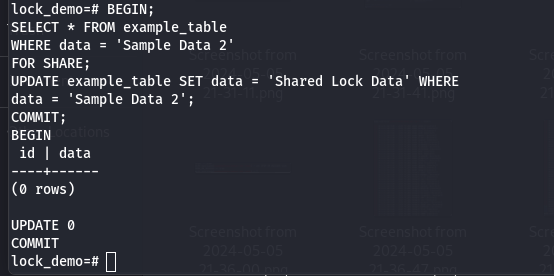
FOR SHARE: Acquires a shared lock on the selected rows, preventing other transactions from acquiring exclusive locks but allows updates within the same transaction.
Concurrency Control Approaches
There are several approaches used for concurrency control in database systems to ensure the isolation property of transactions and maintain data integrity and consistency in the presence of concurrent access. The main concurrency control approaches are:
- Lock-Based Concurrency Control:
- This approach involves the use of locks to regulate access to shared data items.
- Transactions acquire locks on data items before accessing them, preventing conflicting operations from other transactions.
- Common locking protocols include Two-Phase Locking (2PL), which enforces a growing and shrinking phase for lock acquisition and release.
- Variations like multigranular locking and intention locks are used to balance concurrency and overhead.
- Timestamp-Based Concurrency Control:
- In this approach, each transaction is assigned a unique timestamp upon its arrival.
- Conflicts between transactions are resolved based on their timestamps, following either a “wait-die” or “wound-wait” strategy.
- Transactions with older timestamps are typically given priority over newer transactions in case of conflicts.
- Optimistic Concurrency Control:
- This approach assumes that conflicts among transactions are rare and allows transactions to execute without initially acquiring locks.
- Transactions perform their operations on a private copy of the data.
- Before committing, a validation phase checks for conflicts with other concurrent transactions.
- If conflicts are detected, the transaction is aborted and rolled back; otherwise, it can commit its changes.
- Multi-Version Concurrency Control (MVCC):
- This approach maintains multiple versions of data items, allowing transactions to access a consistent snapshot of the data.
- Transactions can read older versions of data without being blocked by writers.
- Writers create new versions of data items without overwriting the versions being read by other transactions.
- MVCC is particularly useful in read-intensive workloads and can provide higher concurrency than locking-based approaches.
The choice of concurrency control approach depends on various factors, such as the workload characteristics (read-intensive or write-intensive), the level of concurrency required, the acceptable overhead, and the database system’s specific requirements and constraints. Some database systems may combine multiple approaches or employ hybrid strategies to optimize concurrency and performance.